Table of Content
OpenZeppelin’s Step-by-Step Approach to Incident Response
Introduction
The primary goal of any blockchain security mechanism is to limit the loss of funds. The ongoing malicious exploitation of smart contracts demonstrates that audits are just one piece of the security puzzle. The next piece is Incident Response; the organized approach and set of procedures taken to identify and manage security breaches or other significant adverse events related to on-chain and off-chain components. The primary goal of incident response is to handle exploits in a manner that:
- Limits lost user and administrative funds.
- Reduces recovery time and costs
- Maintains the reputation of the exploited project
Importantly, a thorough incident response program – implemented as we describe below – runs all the time in real-time. It’s an additional layer of security complimenting the point-in-time nature of a security audit.
Challenges
In conversations with clients and outside projects, the idea of Incident Response is appealing. Who doesn’t want to stop the loss of funds? On the other hand, a comprehensive incident response program often runs into internal resistance. Resistance breaks down into two categories for understandable but not insurmountable reasons.
First are business and process issues. The reader is not alone in thinking, “We really should put an Incident Response plan in place but we are focused on deploying our next update.” or “Setting up a program seems like such a big organization effort that we’ve just got to take our chances.” Incident Response is a complex process that requires specialized expertise, a cultural focus on security, and the orientation and training of resources to address the real-time nature of breaches. But, as we shall see, business and process challenges can be overcome through a step by step approach.
The second category of challenges group around technology issues. We hear statements like, “The atomic nature of blockchain transactions limits our ability to stop attacks in progress and recover already lost funds.” Or, “The high noise to signal ratio of current monitoring tools makes pinpointing real breaches before funds are gone really difficult, if not impossible.” These – and other technological challenges – are valid. However, effective tools exist today and tools must be implemented in concert with an overall plan.
In fact there are instances where breaches have been identified and stopped before the entire funds at risk were drained. One such example is dice9win where the protocol team was able to withdraw funds from a vulnerable contract after ~$25k was stolen but before the remaining $200k. Another example is Badger DAO who paused their contracts, preventing transfers after an attacker managed to steal ~120M over ~2.5 hours through malicious token approvals.
OpenZeppelin’s Step-by-Step Approach to Incident Response
Effective incident response is achievable, but it takes a combination of preparation and commitment, organized skills and training, and technology. With the right guidance and proper approach – as outlined below – avoiding disastrous outcomes is achievable.
Incident Response Components
A comprehensive incident response program can be broken down into five primary phases:
- Identification
- Preparation
- Detection
- Response
- Improvement
 1. Threat Identification
1. Threat Identification
The first step is to identify what threats your protocol faces and understand how you’re mitigating risk in the presence of each threat. Every protocol will face unique threats based on its contract architecture, off-chain infrastructure, and business processes. Threat identification is typically done through threat modeling exercises where developers and security researchers evaluate the system and its interconnected components, identifying how specific types of risks might impact the system. Once all the risks have been identified, each risk is evaluated with an overall risk rating defined by how easy it is to exploit, how easy it is to mitigate, and how impactful the risk would potentially be. The example below shows 2 entries of a sample risk matrix for a DeFi project.
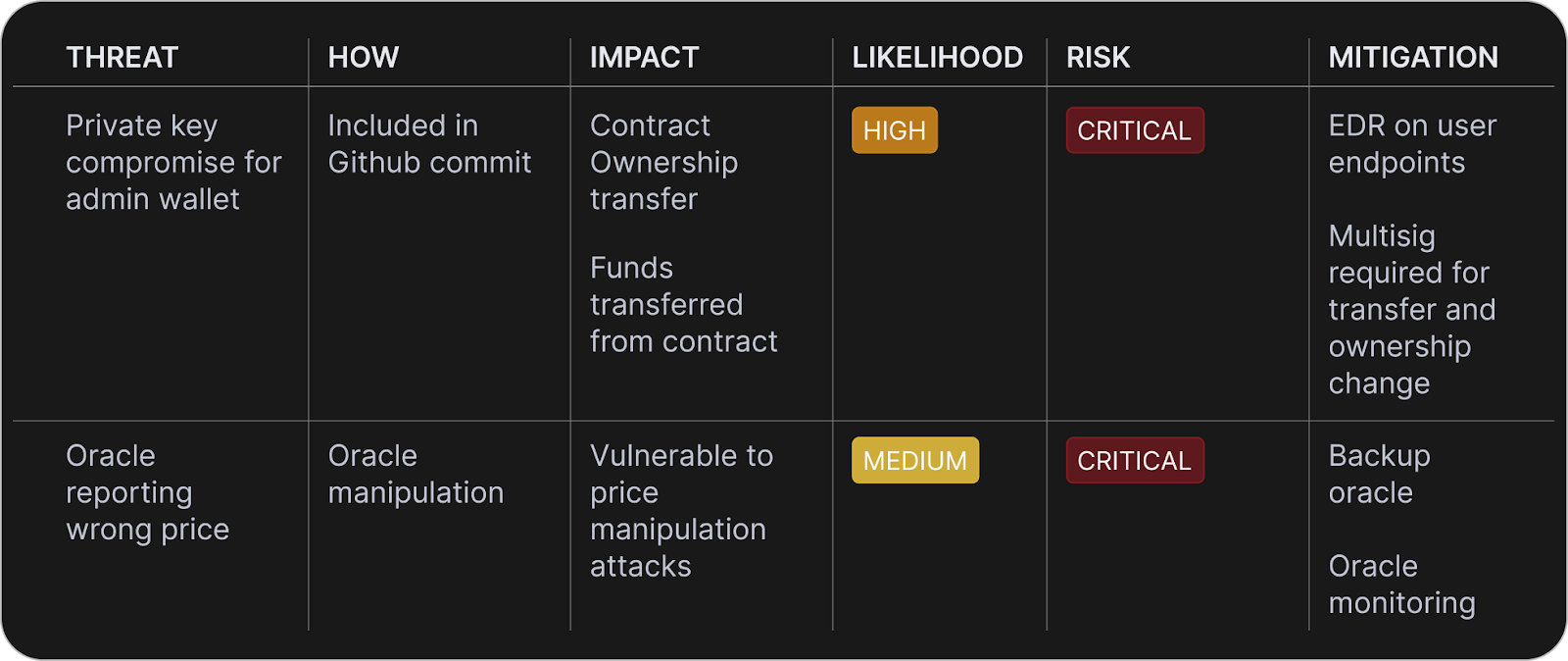
Benefit: Identification of risk through threat modeling provides the foundation for the rest of the incident response process. The first step in mitigating risk is identifying what those risks are.
Output: Comprehensive matrix of all potential threats to the system and understanding how to reduce the overall security risk to the system.
2. Preparation
With as many threats as possible identified, the next step is to prepare for how to handle threats that cannot be eliminated. This phase consists of:
- Creating a comprehensive incident response plan that documents and details how to handle each threat along with general response processes
- Implementing the necessary tooling and procedures
The outline below provides an example for the types of activities that are included in a well documented incident response plan.
- Personnel
- Team members
- Roles and responsibilities
- Preparation
- Documentation
- Internal communication
- Public communication
- Logging
- Metrics
- Detection
- On-call rotation
- Bug bounty triage
- Alert escalation
- Analysis
- Shallow root cause checklist
- Full root cause checklist
- Mitigation
- On-chain mitigation actions
- Off-chain mitigation actions
- Recovery
- Upgrades
- Key rotation
- Attacker negotiation
- Stolen fund tracking
- Post-mortem
- Threat scenario playbook
Tooling exists across the incident response lifecycle and refers to tools like PagerDuty or OpsGenie that support the incident management process, monitoring and automation tooling like OpenZeppelin Defender, and incident investigation tools like Chainalysis KYT and transaction tracer.
This phase can be resource intensive but the labor can be reduced by leveraging your protocol’s existing internal documentation and experience in troubleshooting issues that arise during the development, deployment, and maintenance of your protocol.
Benefit: The goal of the incident response plan documentation is to reduce the need for in-the-moment decision making; to have a well thought out strategy for responding to security incidents prior to the response process. Incident Identification and response will be chaotic without adequate prior organization.
Output: Detailed Incident Response Plan that documents the processes, personnel, and tooling necessary for effectively responding across a wide range of security incidents. The plan is set up to be stress tested in live simulations, and thus continually improved.
3. Detection
Without proper threat detection, protocols may be left in the dark – only to find out that they’ve been exploited after significant funds have gone missing or because of some random notification on Twitter. Robust monitoring platforms such as Forta bots and others are recommended to provide both custom protocol-specific detections as well as generic threat detection. Threat modeling provides guidance for detection. The monitoring stack can thus identify threats that cannot be entirely eliminated. This process may be resource intensive but it also puts protocols in the best position to detect threats early, reducing the amount of funds lost and limiting the damage and cost to the protocol.
Benefit: The best threat detection implementations leverage generic attack detection and build custom monitoring of complex protocol-specific threats related to the specific workings and invariants of the protocol.
Output: A cohesion of monitoring that detects invariant deviations, protocol health factors, administrative changes, dependencies, and risk parameters that indicate a protocol might be under attack.
4. Response
With sufficient threat detection in place, protocols must now enable on-chain and off-chain response mechanisms to ensure that when a threat is detected, they are able to respond appropriately. This will look different for different protocols but some examples of common incident response mechanisms include:
- Pausing
- Withdrawal or borrow limits
- Rate limiting
- Blocklists or allowlists
- Reputation systems
Deciding which type of response mechanism is best depends on the project type, risk profile, technical implementations, composability expectations, and regulatory environment. For additional context on the state of current incident response mechanisms see Smart Contracts: Insights on Current Mechanisms and The Future of Threat Prevention in Web3.
The response process is where all the preparation and planning come into play. Organizations set up a “war room” with all the relevant experts and the team analyzes the incident, decides on an appropriate mitigation, implements the appropriate response, and discusses how to communicate publicly. This process is typically run by someone with an “Incident Commander” role but if done properly, everyone will already be familiar with the incident response plan and their roles so the response process can follow the established plan. There will always be room for nuance depending on the nature of the incident but having the high level response process documented gives the team the resources to respond quickly and effectively.
One of the key challenges in blockchain incident response is the atomic nature of transactions makes it difficult to detect exploits until after they happen and response often only occurs after some funds are taken. However, many exploits and less sophisticated attackers require multiple transactions to fully take advantage of a vulnerability or drain a protocol. This provides an opportunity to implement automated circuit breakers that take an incident response action as soon as an exploit is detected, preventing copycat attackers and additional exploiting, reducing the overall amount of funds lost. For example, in the Euler hack only ~$9M in DAI was stolen in the first transaction with the rest of the ~$197M in stolen funds taken in subsequent transactions between 6 minutes and 16 minutes after the first transaction. Or in the case of Exactly, there was a copycat attack approximately 3 hours after the initial hack.
Benefit: Effective response is empowered by a strong and well communicated set of internal procedures and guidelines that, when combined with the appropriate tooling, allow an organization to respond clearly, immediately, and effectively.
Output: Decision trees and processes around the ability to triage and respond to ongoing incidents in a clear and effective manner that mitigates loss of funds and reputation of the protocol.
5. Improvement
It’s challenging to get this complex process correct on the first attempt, but running attack simulations gives protocols the opportunity to test the response processes and make improvements prior to an actual incident. Tracking metrics such as detection time, analysis time, and mitigation time with each iteration provides the necessary data to identify areas of improvement, optimize the plan for each protocol, team, and toolset, and foster a security culture in the team.
Benefits: Incident response simulations provide teams the opportunity to evaluate and improve when the stakes are low while also giving the team familiarity with processes that they’ll rely on in times of crisis.
Output: An evaluation of a team’s response capabilities that includes effectiveness metrics, areas for improvement, and strengths to drive further refinement and improvement of the incident response process.
Conclusion
A solid incident response program is well documented, comprehensive, sufficiently tested, well communicated, and flexible enough to evolve as the protocol does. It requires significant resources and security investment. With the right expertise and approach a comprehensive incident response plan is in reach for all blockchain protocols, helping reduce lost funds and driving blockchain technology toward a more secure future.
Get Started with Incident Response
Check out our Incident Response Scorecard evaluation to assess how prepared your protocol is. Reach out to us here to learn more about the services we offer so that you can be better prepared to handle your next security incident.


