We describe a vulnerability in the Move IR compiler whereby inline comments can be disguised as executable code. This is due to the Move IR parser failing to recognize some Unicode line break characters at the end of inline comments. In particular, while the code intends to parse the common \r, \n and \r\n, it fails to parse \r correctly. Additionally, other valid Unicode line break characters are ignored entirely by the parser.
The potential impact of the vulnerability can vary greatly and depend on i) the business logic of each specific module and its use cases, ii) current and future features of the Move IR language, and iii) the developer platform being used to submit bytecode to the Libra network. Some potential exploiting scenarios one can think of are:
- A faucet that mints assets (Libra Coins or any other asset on the Libra network) in exchange for a fee can deploy a malicious module that takes a fee but never actually provide the possibility of minting such asset to the user.
- A wallet that claims to keep deposits frozen and release them after a period of time may actually never release such funds.
- A payment splitter module that appears to divide some asset and forward it to multiple parties may actually never send the corresponding part to some of them.
- A module that takes sensitive data and applies some kind of cryptographic operation to obscure it (e.g. hashing or encrypting operations) may actually never apply such operation.
By crafting modules with specific line break characters different from \n at the end of inline comments, malicious module publishers can deceive users that trust their apparent source code. This is especially important in the blockchain setting, where trust is replaced by auditability. A related vulnerability was previously found by our team in the Solidity compiler audit on Nov 1st, 2018.
The events timeline is as follows:
- August 6th: We disclosed the vulnerability to the Libra team, who acknowledged our notification.
- August 8th: The Libra team introduced a change to the line of code where we had pinpointed the vulnerability. The vulnerability was still present after this change. Upon checking in with them, they stated that the code change was unrelated to the vulnerability, and acknowledged that it didn’t fix the problem. We provide a technical description of the vulnerability in the patched code in the Code change section.
- September 3rd: The Libra team pushed a fix for the vulnerability and notified us about it.
- September 4th: We reviewed the patch, confirming that the vulnerability has been fixed. We provide details about this patch in The fix section.
Details
We first explain where the vulnerability is, to then introduce two critical scenarios under which it could be exploited to disguise inline comments as executable code. The exploit relies on the fact that different text editors interpret and render line breaks in different ways. This could be leveraged by malicious actors entitled to publish Move modules in the Libra network to deceive users, who would then interact with modules behaving in unexpected ways.
While this feature is restricted to a set of trusted users today, it could potentially be open, public and permissionless in the future. In The exploit section we showcase a simple proof-of-concept Move module with a single resource declaration; more dangerous cases can be thought of in modules that handle valuable assets.
The vulnerability
In the Move IR compiler code at commit 8ea3329, within the strip_comments function, the parser module tries to identify inline comments with a simple regular expression intended to match comments that end in \r, \n or \r\n:
fn strip_comments(string: &str) -> String {
// Remove line comments
let line_comments = Regex::new(r"//.*(\r\n|\n|\r)").unwrap();
line_comments.replace_all(string, "$1").into_owned()
}
We have identified two cases where the parser fails:
- The above function silently fails at detecting the end of an inline comment marked with the
\rcharacter. - The above function ignores several other Unicode characters lawfully representing line breaks.
Case 1
The Move IR parser uses a regular expression from the regex Rust crate to detect inline comments in the code of Move modules. It attempts to match inline comments ending with \r\n, \n or \r using:
Regex::new(r"//.*(\r\n|\n|\r)")
However, the regular expression does not actually behave as expected, as it does not actually detect the end of inline comments marked by the \r line break character.
In order to understand the exact behavior of the erroneous regular expression, we explain each of its components individually.
- The
rbefore the double quotes is a Rust feature to identify a “raw string literal”, used just as a convenient way to write the regex string as-is without having to escape special characters. //: matches the start of the Move IR inline comment syntax..*: matches zero or more characters except for the line break character\n.This is due to historic reasons, as regexes were originally used in line-based tools. The behavior is documented in theregexRust crate as follows: “[The character] . will match any valid UTF-8 encoded Unicode scalar value except for\n“.(\r\n|\n|\r): is a capturing group matching characters\r\n,\n, or\r, attempting to identify the end of the inline comment.
In general, a regex engine walks through the regular expression attempting to match the next token in the regex to the next character in the string. If a match is found, the engine advances through the regex and the subject string. In our case, every character in a Move IR inline comment will be first matched by the .* expression except for \n, as explained in point 3. Crucially, however, the \r character will be among those matched by .*. When the engine finally finds a \n in the string, it will stop consuming further characters.
What this entails is that the parser will only identify \n as the end of the inline comment, silently failing to identify \r as a line terminator. In other words, just as any other regular character, \r is considered as part of the comment instead of as its ending.
In The exploit – Case 1 section we show a proof-of-concept case of a malicious Module that takes advantage of how a major editor renders the \r character.
Case 2
The Move IR parser intends to handle the most common line break characters CR (\r), LF (\n) and CRLF (\r\n). Besides failing to parse \r correctly, as described in The vulnerability – Case 1, there are several other Unicode characters representing line breaks that the parser does not even attempt to detect. The complete set of Unicode line break characters is:
- LF (
\nor0x0Ain hex) - VT (
\vor0x0Bin hex) - FF (
0x0Cin hex) - CR (
\ror0x0Din hex) - CRLF (
\r\nor0x0D0Ain hex) - NEL (
0xC285in hex) - LS (
0xE280A8in hex) - PS (
0xE280A9in hex)
Characters LF, CR and CRLF are the most widely recognized line breaks. Yet several code editors, the popular Visual Studio IDE among them, still properly render some of the less common line break characters such as NEL, LS or PS. As in Case 1, this can lead to malicious Move Modules that are hard to detect. Such examples are showcased in The exploit – Case 2 section.
The exploit
Any malicious actor entitled to deploy a module to the Libra network can leverage the described vulnerability. By crafting malicious modules with specific line break characters different from \n at the end of inline comments, they can deceive users that trust the apparent source code of the module, tricking them into executing undesired actions. This is especially important in the blockchain setting, where trust is replaced by auditability.
The nature of the deception can vary greatly and depend on i) the business logic of each specific module and its use cases and ii) current and future features of the Move IR language. Some potential exploiting scenarios one can think of are listed in the Summary section.
As a proof of concept, we now present two cases of malicious modules that respectively take advantage of both cases described in The vulnerability section. All test files referenced in this write up can be found in a private repository: https://github.com/OpenZeppelin/move-compiler-vulnerability.
Case 1: \r
Several code editors and renderers (e.g. Visual Studio Code, Sublime Text, Gedit, GitHub) consider the \r character (0x0d in hex) a valid line break. This means that these editors will show an inline comment and the following instruction in two different lines when separated by a \r. For example, the following Move module, as rendered by GitHub, appears to be declaring a resource.
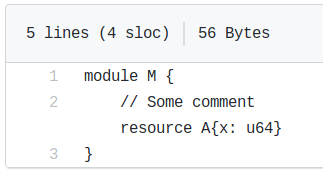
But at the end of the inline comment there is an invisible \r line break character, which can be detected via inspection of the file’s hexdump:
$ xxd Module_CR.mvir
00000000: 6d6f 6475 6c65 204d 207b 0a20 2020 202f module M {. /
00000010: 2f20 536f 6d65 2063 6f6d 6d65 6e74 0d20 / Some comment.
00000020: 2020 2072 6573 6f75 7263 6520 417b 783a resource A{x:
00000030: 2075 3634 7d0a 7d0a u64}.}.
As explained in The vulnerability – Case 1 section, the above module will actually be compiled as an empty module.
In the Validating with the Move IR compiler output section we demonstrate the scenario with a more in-depth comparison of the compiler’s bytecode produced for regular and malicious Move modules.
Case 2: other line break characters
The most commonly accepted line break characters are \n, \r and \r\n. But as we already stated, the way in which text editors render line break characters differ from editor to editor. Here is how the Visual Studio IDE editor (widely used by software developers) renders a very simple Move module with the common \n line break between the inline comment and the resource declaration:

But this editor interprets not only LF as a valid line break, but also CRLF, NEL, LS and PS.
Following we show how Visual Studio IDE shows the same simple module but with PS, NEL and LS line breaks respectively:



A user reading Move module’s code from any of these three last files using the Visual Studio IDE can be tricked into believing that the M module is declaring a resource, whereas the Move IR compiler will consider that instruction as part of the inline comment.
As exhibited in the screenshots included in the images folder, the Unix command line cat as well as GNOME’s Gedit also display a similar behavior, unlike other major editors such as Visual Studio Code, Atom, Sublime Text, or the GitHub online editor.
Validating the Move IR compiler output
For the sake of simplicity, we showcase the compiler’s output using two simple proof-of-concept modules, each corresponding to the cases 1 and 2 described previously. Yet, the following can be reproduced for all other line break characters that the Move IR parser fails to detect. The compiler we used was built from the latest commit to the date, 8ea33298678117748f1c75112f35a9fbc05b2172.
First, compile a simple non-malicious Move module with an inline comment and a resource declaration where all line breaks are \n (see Module_LF.mvir):
$ ./compiler Module_LF.mvir --module --output lf-output
The output in this case is:
$ xxd -ps lf-output 4c49425241564d0a0100080153000000020000000255000000040000000b 59000000020000000d5b00000002000000055d0000000600000004630000 002000000008830000000400000009870000000300000000000001010001 020300014d01410178000000000000000000000000000000000000000000 000000000000000000000000020100000200
Now compile a non-malicious Move module without a resource declaration (see Module_Commented.mvir):
$ ./compiler Module_Commented.mvir --module --output commented-output
$ xxd -ps commented-output 4c49425241564d0a010004012f000000020000000d310000000200000005 330000000200000004350000002000000000000300014d00000000000000 00000000000000000000000000000000000000000000000000
Let’s now compile two different malicious Move modules that disguise an inline comment as executable code. First, corresponding to Case 1, the line break between the inline comment and the resource declaration will be the CR character (\r or 0x0D in hex; see Module_CR.mvir):
$ ./compiler Module_CR.mvir --module --output cr-output
The output in this case is:
$ xxd -ps cr-output 4c49425241564d0a010004012f000000020000000d310000000200000005 330000000200000004350000002000000000000300014d00000000000000 00000000000000000000000000000000000000000000000000
Next, as an instance of Case 2, the line break between the inline comment and the resource declaration will be the PS character (0xE280A9 in hex; see Module_PS.mvir).
$ ./compiler Module_PS.mvir --module --output ps-output
Similarly, the output in this case is:
$ xxd -ps ps-output 4c49425241564d0a010004012f000000020000000d310000000200000005 330000000200000004350000002000000000000300014d00000000000000 00000000000000000000000000000000000000000000000000
Note that the bytecode produced in both cases is identical to the bytecode produced in the case of a module without a resource declaration. This demonstrates that the compiler indeed misses the resource declaration in modules where comments are terminated with the CR and PS line break characters.
Code change
In commit 5fb715e, the Libra team introduced changes to the lines of code affected by the vulnerability and modified the regex used to identify inline comments within the strip_comments_function. The improved code results in a more concise way to match comments that end with a newline (\n) character, but is still vulnerable to the possibility of disguising inline comments as executable code. Let’s take a closer look to the code:
fn strip_comments(string: &str) -> String {
// Remove line comments
let line_comments = Regex::new(r"(?m)//.*$").unwrap();
line_comments.replace_all(string, "$1").into_owned()
}
The regular expression which is used to match inline comments works fine when using \n as a line break character, but, as was the case with the original one, lacks the ability to detect the end of inline comments marked by \r or other Unicode line break characters.
In order to understand the exact behavior of the new erroneous regular expression, we explain each of its components individually:
- As before, the
rbefore the double quotes is a Rust feature to identify a “raw string literal”, used just as a convenient way to write the regex string as-is without having to escape special characters. - The
(?m)flag symbolizes the multi-line mode, which means that the^and$no longer match just the beginning/end of the input, but the beginning/end of lines. - As before,
//matches the start of the Move IR inline comment syntax. - As before,
.*matches zero or more characters except for the line break character \n. $is a special character that matches the newline (\n) character. Is it explicitly explained in the documentation of the regex crate that this character does not match other Unicode line break characters, including the\rline break.
To summarize, this regular expression works exactly as the previous one in terms of not matching any other line break except from the \n character, resulting in the same attack vectors and exploitation explained on the original report, based on the same Move IR modules originally used to illustrate the vulnerability.
The fix
In commit 7efb022 the Libra team fixed the vulnerability by introducing a strip_comments_and_verify function, which in turn calls the verify_string function before actually stripping the comments. This function makes sure that all characters in the string are permitted characters through the is_permitted_printable_char and is_permitted_newline_char functions. These functions validate the characters by making sure they lie within a limited range of the whole character set. In particular, the only newline character explicitly allowed is \n (0x0A), and the \r and other more esoteric newline characters are outside the range defined in the is_permitted_printable_char function.
We have validated this fix with all our new line character test cases. Apart from the \n case, which works as expected, all other test modules now give rise to a compile time parser error.
Conclusion
We demonstrated that Move modules could disguise inline comments as executable code, due to a vulnerability in the language’s parser. Malicious actors entitled to publish Move modules in the Libra network could deceive users who would interact with modules behaving differently than expected. We conclude that no Move IR module file with inline comments could be trusted to behave as expected without a deeper analysis of the file’s real content or the actual bytecode produced after compilation as long as the vulnerability is not fixed.
Two scenarios were explored, the most critical one being how the source code of the Move IR parser can deceive developers and auditors into believing that a widely-used line break character is recognized as a valid inline comment ending, while it is actually not. To fix the vulnerability, we recommended that Move’s development team modified the regex in the strip_comments function so as to correctly parse the \r character along with all other Unicode characters that represent a line break. To increase the software’s transparency, thorough and extensive unit testing considering Move modules with all different line breaks was also recommended.
After a code change unrelated to the issue, the vulnerability was fixed by the Libra team in commit 7efb022.


