Table of Content
Current State: How is IR being Done Now
Best State: Requirements for Effective Incident Response
Best State: Technical Response Mechanisms
Blockers: Why is there a lack of Incident Response?
Introduction
Weekly attacks on smart contracts in the blockchain industry have proven one thing: Audits shouldn’t be the only tool employed to protect the security of assets and prevent the loss of funds. Additional layers of security are needed. Incident Response has been effective in the traditional security space for decades to mitigate the loss of compromised assets and protect organizations’ reputations. Now the blockchain industry is adopting more robust incident response practices to integrate with their existing monitoring stacks in ways that directly address the nuances of blockchain technology.
In this post, we’re going to explore the current state of incident response in the blockchain industry. Next, we’ll focus specifically on the technical response mechanisms that are available for protecting assets managed by smart contracts.
Current State: How is IR being Done Now
Despite the lack of widespread Incident Response practices across the industry, there are a few organizations and protocols that have implemented incident response protocols alongside their existing security stack. Primary components of the current incident response layer include:
1. Community Whitehats
The most visible incident response group right now is SEAL911, a group of industry volunteers including participation of OpenZeppelin’s Incident Response lead, who help protocols respond to security incidents, and recently prevented a major loss before it happened. Other community whitehats are active in reporting, analyzing, and helping to prevent losses by exploiting bugs during ongoing incidents with the intention of returning the funds. However, relying on community volunteers is not reliable enough for protocols who need to speed up response processes by leveraging an internal team with intimate knowledge of their protocol.
2. Governance security council
Some organizations, such as Lido, Matter Labs, and Curve, have adopted the idea of decentralized security governance through a multisig security council. The multisig that controls their incident response functionality includes security experts that provide guidance on when to activate incident response functionality. This model provides a middle ground between volunteer-based whitehats and internal teams but the consensus driven model can still be slow in times of urgent response.
3. Automation
Automation is a recurring theme for fast incident response and often is the linchpin for effective incident response strategies. By defining risk parameters and security policies around when incident response functionality, like a pause, should be used, certain alerts can trigger the execution of automated on-chain actions. While timely detection forms the cornerstone of prevention, on-chain response automation enables rapid actions to prevent or mitigate ongoing attacks. However, automation only works if the alerting is well-tuned to minimize the false-positive rate to near zero and only produce high-fidelity alerts.
Best State: Requirements for Effective Incident Response
Before you can respond to incidents on-chain there are a couple of prerequisites:
- Monitoring and Detection
- Response mechanisms in the contract
- Internal policies for when and how to use the mechanisms
1. Monitoring and Detection
The first requirement is the ability to identify an incident by monitoring specific parameters that present a threat to the protocol. There are a number of vendors that offer generic monitoring services and they tend to detect threats in similar manners using heuristic identification, reputation systems, pattern matching, anomaly detection, and AI models. As an example, the decentralized monitoring platform Forta uses bytecode matching in its Attack Detector Feed to detect attack activity before funds are stolen, allowing teams to react before a loss occurs. More custom monitoring of specific protocols involves looking at protocol invariants and detecting when those invariants are broken, indicating a compromise.
2. Response Mechanisms
Once detected via monitoring, effective response to incidents requires functionality at the smart contract level. The most common function today is a pause on the protocol, such as the one used by USDC shown in the images below.
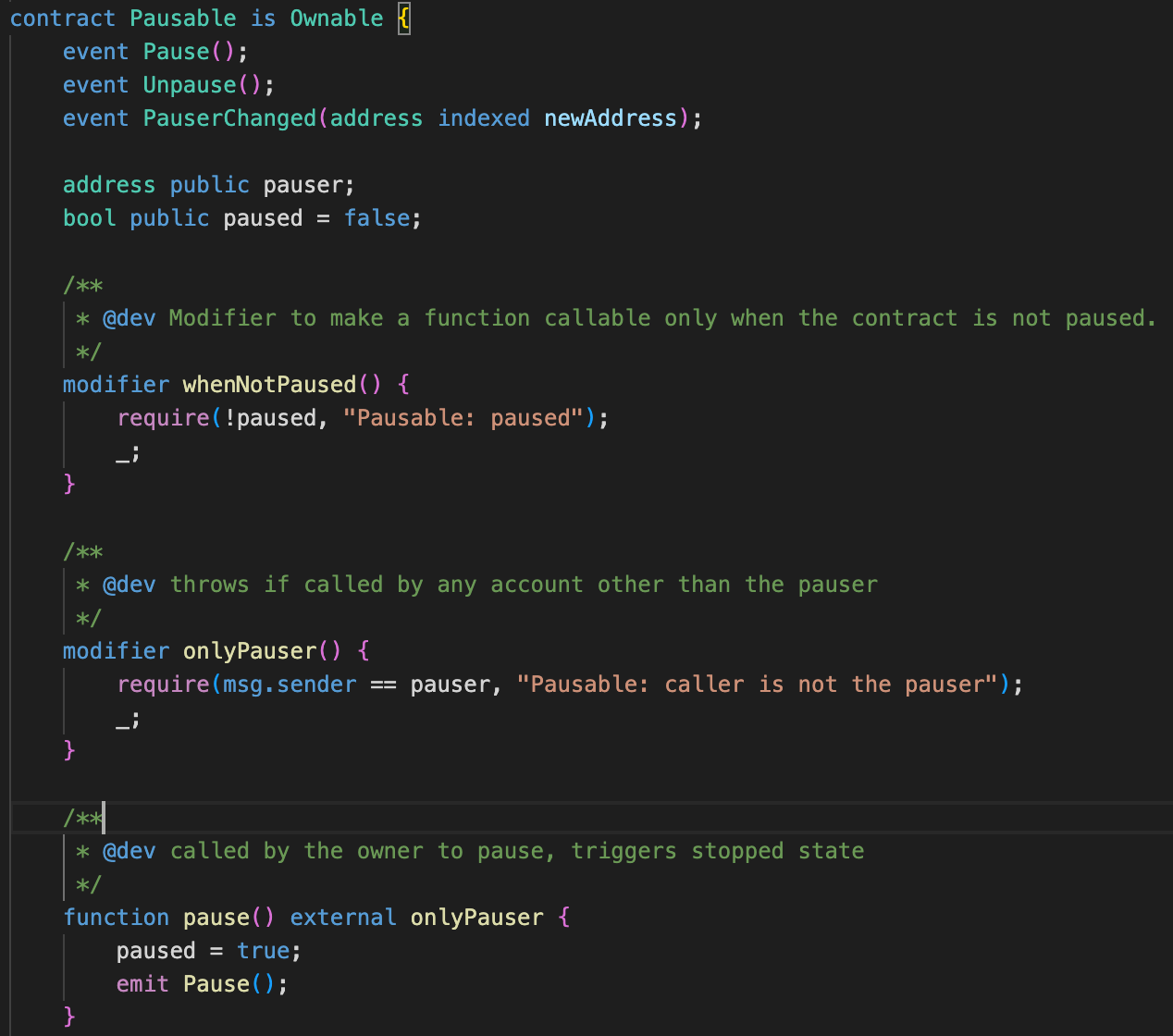
We’ll expand on specific mechanisms in more depth in later sections.
3. Policies
With the technical components in place, organizations are faced with the task of developing use cases for when and how these technical on-chain mechanisms are used. This is sometimes done through governance like a DAO, multi-sig security council, or with an internal security or development team. For example, the DeFi protocol Compound uses a Pause Guardian multisig that includes a mix of community members, security partners such as OpenZeppelin, and the Compound Labs team. OpenZeppelin worked with the multisig members and Compound Labs to develop a set of security policies that govern use of the multisig. The security policies should complement the technical response mechanisms so that they are used as effectively as possible.
Best State: Technical Response Mechanisms
Having looked at the requirements for effective incident response, what on-chain response mechanisms actually exist today? We’ll look at the following most common technical response mechanisms:
- Pausing
- Function limits
- Allowlisting and blocklisting
- Rate limiters
- Settlement timelocks and batch reversion
- Frontrunning
1. Pausing
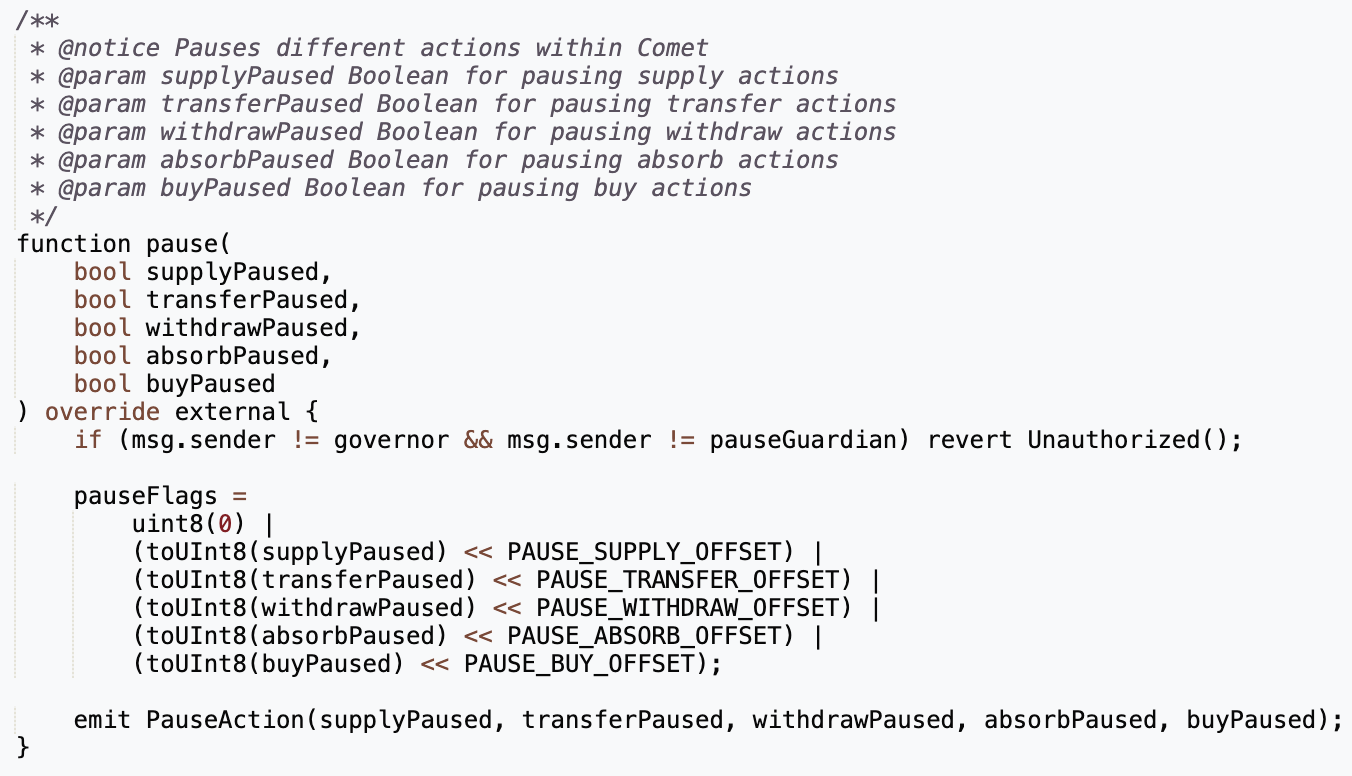
Pausing has become a default response mechanism and is implemented in two ways. First, at a broad level with the whole protocol being halted. Second, on a granular level where individual pieces of functionality are paused, an example of which is shown below from Compound.
OpenZeppelin’s contracts library includes a standardized implementation of pausing in the Pausable.sol contract that provides whenPaused() and whenNotPaused() function modifiers. While it’s an effective measure if executed before the protocol is exploited, it creates a denial of service condition for all other users and trades off integrity for availability until a fix can be applied via upgrade.
One such pause mechanism that is currently being discussed among the community is EIP-7625: Circuit Breakers, which provides a contract standard that “triggers a temporary halt on protocol-wide token outflows when a threshold is exceeded for a predefined metric”.
2. Function Limits
Referring back to Compound as an example, they can also modify supply caps, borrow collateral, liquidation factors, and asset price feeds to mitigate damage in the event of a security incident. An example of some of the functions that allow these modifications is shown below.

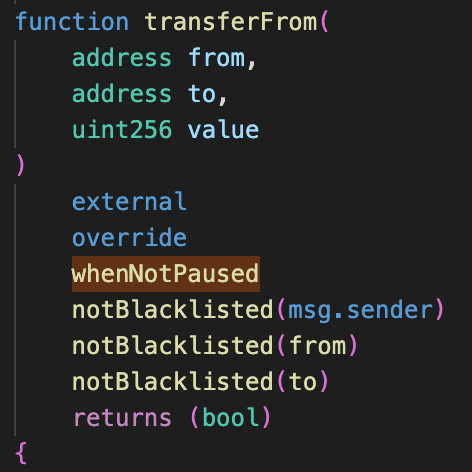
3. Allowlisting and Blocklisting
Allowlisting most commonly exists as a mechanism for projects to give a subset of users early access to a protocol, but it can also be a useful tool for restricting feature access to a trusted set of addresses. Blocklisting is the opposite of allowlisting and assumes all addresses are allowed unless specified otherwise. Stablecoins like USDC, code shown below, implement a blocklist to maintain compliance with OFAC sanctioned addresses.
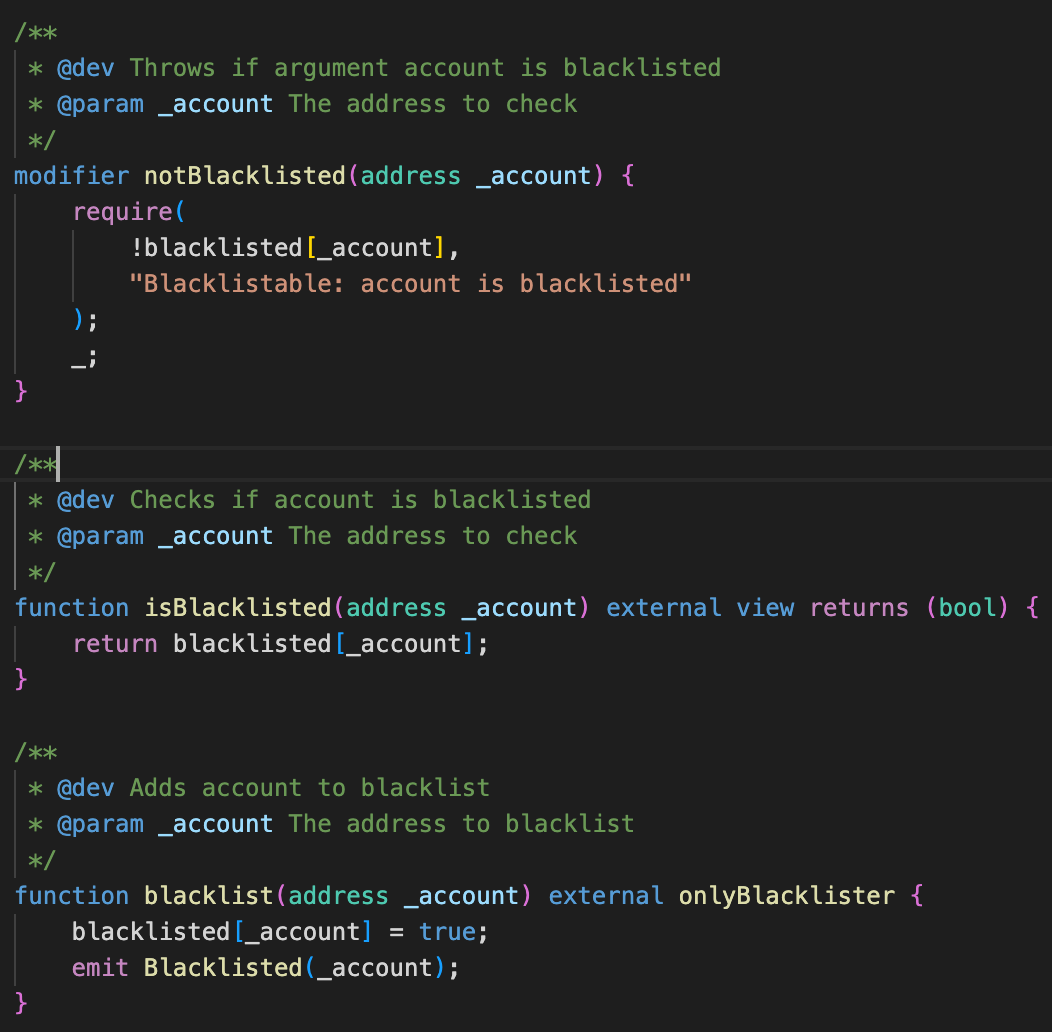
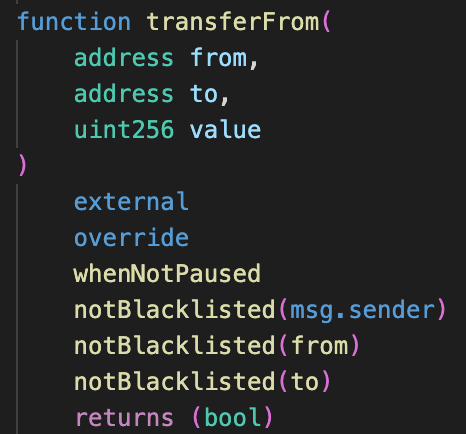
It is most commonly used to prevent known malicious addresses from interacting with a protocol or transferring tokens. Allowlisting is more secure than blocklisting but can also be an overly burdensome and restrictive tool that prevents legitimate users from interacting with a protocol.
4. Rate Limiters
Rate limiting, specifically withdrawal rate limiting, is used by projects to minimize damage, limiting the amount of funds a user can withdraw at one time. Chainlink CCIP implements rate limits that “are enforced at both the source and destination blockchains for maximum security” through the AggregateRateLimiter.sol contract. This minimizes the amount of funds an attacker would be able to withdraw in a given time period, forcing them through multiple withdrawals and giving protocols the time to identify the incident and react. However, this also impacts regular users who are limited in the amount of funds they can move in a defined time period and can cause friction in the user experience.
5. Settlement Timelocks and Batch Reversion
Some L2 rollup projects like Matter Labs implement settlement timelocks where the L2 blocks aren’t finalized on L1 until a set time period is passed. This gives protocols the opportunity to identify incidents and revert L2 batches before they are finalized on L1. It should be noted that Matter Labs plans to eventually remove the settlement timelock.
6. Frontrunning
With blockchain technology, attacks often happen in seconds or minutes with millions of dollars gone in a single transaction. Transaction frontrunning involves monitoring public mempools, for exploit transactions, and then submitting a transaction with a higher gas price so that it gets picked up by miners before the original exploit transaction to exploit the protocol before the attacker has a chance to. This is mostly done by individual community whitehats but there have been a few instances where companies have been able to front-run exploit transactions before an attacker. The effectiveness of front-running is limited by the availability of private mempools and services like flashbots.
Blockers: Why is there a lack of Incident Response?
With all of these mechanisms available, what's stopping more projects from implementing on-chain response mechanisms? There are currently a few barriers to making these mechanisms more widespread:
- Gas optimization
- Focus on prevention over mitigation
- Code is law
- Censorship
- Composability
1. Gas Optimization
The increased focus on gas optimization has driven protocols towards a bare minimum implementation of security features and checks, with incident response mechanisms often being sacrificed to save a few wei per transaction in gas. The peace of mind and benefit of an additional security layer outweigh the small increase in gas. On L2 networks, cheap gas costs reduce the impact but this may change as the demand for blockspace grows relative to the supply. Ultimately, we can expect users and protocols to be willing to pay a little bit more in gas for the benefit of more secure funds and transactions.
2. Prevention over Mitigation
Other protocols feel that because these features often can’t prevent exploits outright but instead are mitigative measures, they’re not worth including in the contract. Yet several of the largest hacks this year occurred over multiple transactions. Rapid response could have prevented hundreds of millions of dollars in stolen funds which occurred after the first malicious transaction took place.
3. Code is Law
We’ve heard some protocols say that “if I can anticipate the threat I can handle it in the contract code”. While this is sometimes the case, the fact that we continue to see exploits of audited code proves that there is a necessity to prepare for unexpected threats as well and introduce multiple layers of security. Some threats, such as a private key compromise, can’t be completely eliminated with on-chain code, and thus require technical (and non-technical) response mechanisms.
4. Censorship
Certain incident response strategies can resemble centralized rug pulls. For instance, transferring funds to a backup wallet, revoking access, and blocklisting might be incident response tactics but can also be indicative of centralized projects or contracts facilitating malicious activities. Users are wary of projects that have these types of mechanisms, and rightfully so. Over time, protocols will gain the trust of their users and additional technical mechanisms will provide the users with more comfort that these controls are used to save their funds, not steal them.
5. Composability
One of the primary benefits of blockchain protocols is their composability: the ability to seamlessly integrate with other decentralized components to create a larger, more complex system. When one piece of the system is paused or its behavior is changed in a way that other protocols depend on, it can cause downstream effects that get messy and can discourage builders. In reality, when a protocol faces an attack and is subsequently paused, it acts as a protective shield for other integrating protocols. Any transactions directed to these integrated protocols would be reverted, thereby reducing the actual complexity and potential fallout from such an attack.
Conclusion
On-chain incident response mechanisms are growing in popularity and have already shown the ability to mitigate loss of funds. Today, while there is no silver bullet to preventing hacks, projects do have tools at their disposal. Implemented correctly – and as part of an overall plan – they can form several layers of defense. The result: a robust security posture that runs in real-time all the time. Technical response mechanisms are only one piece of a broader incident response strategy and plan. Best Practice incident response plans include fostering a strong internal security culture, preparation and planning for handling incidents, leveraging tooling and expertise, and dedication to continuous improvement through simulation testing. We’ll cover more of what makes up a strong incident response plan in a later blog post. To find out more about how you can better protect your protocol and get assistance with navigating the incident response process, reach out to us here.


